ADOP:
Adop phases and parameters:
Adop phases
1) prepare - Starts a new patching cycle.
Usage: adop phase=prepare
2) Apply - Used to apply a patch to the patch file system (online mode)
Usage: adop phase= apply patches = <>
Optional parameters during apply phase
--> input file : adop accepts parameters in a input file
adop phase=apply input_file=
Input file can contain the following parameter:
workers=
patches=:.drv, :.drv ...
adop phase=apply input_file=input_file
patches
phase
patchtop
merge
defaultsfile
abandon
restart
workers
Note : Always specify the full path to the input file
--> restart -- used to resume a failed patch
adop phase=apply patches=<> restart=yes
--> abandon -- starts the failed patch from scratch
adop phase=apply patches=<> abandon=yes
--> apply_mode
adop phase=apply patches=<> apply_mode=downtime
Use apply_mode=downtime to apply the patch in downtime mode ( in this case,patch is applied on run file system)
--> apply=(yes/no)
To run the patch test mode, specify apply = no
--> analytics
adop phase=apply analytics=yes
Specifying this option will cause adop to run the following scripts and generate the associated output files (reports):
ADZDCMPED.sql - This script is used to display the differences between the run and patch editions, including new and changed objects.
The output file location is: /u01/R122_EBS/fs_ne/EBSapps/log/adop////adzdcmped.out.
ADZDSHOWED.sql - This script is used to display the editions in the system.
The output file location is: /u01/R122_EBS/fs_ne/EBSapps/log/adop///adzdshowed.out.
ADZDSHOWOBJS.sql - This script is used to display the summary of editioned objects per edition.
The output file location is: /u01/R122_EBS/fs_ne/EBSapps/log/adop///adzdshowobjs.out
ADZDSHOWSM.sql - This script is used to display the status report for the seed data manager.
The output file location is: /u01/R122_EBS/fs_ne/EBSapps/log/adop///adzdshowsm.out
3) Finalize : Performs any final steps required to make the system ready for cutover.. invalid objects are compiled in this phase
Usage: adop phase=finalize
finalize_mode=(full|quick)
4) Cutover : A new run file system is prepared from the existing patch file system.
adop phase=cutover
Optional parameters during cutover phase:
-->mtrestart - With this parameter, cutover will complete without restarting the application tier services
adop phase=cutover mtrestart=no
-->cm_wait - Can be used to specify how long to wait for existing concurrent processes to finish running before shutting down the Internal Concurrent Manager.
By default, adop will wait indefinitely for in-progress concurrent requests to finish.
5) CLEANUP
cleanup_mode=(full|standard|quick) [default: standard]
6) FS_CLONE : This phase syncs the patch file system with the run file system.
Note : Prepare phase internally runs fs_clone if it is not run in the previous patching cycle
Optional parameters during fs_clone phase:
i ) force - To start a failed fs_clone from scratch
adop phase=fs_clone force=yes [default: no]
ii ) Patch File System Backup Count ==> s_fs_backup_count [default: 0 : No backup taken]
Denotes the number of backups of the patch file system that are to be preserved by adop. The variable is used during the fs_clone phase,
where the existing patch file system is backed up before it is recreated from the run file system.
7) Abort - used to abort the current patching cylce.
abort can be run only before the cutover phase
adop phase=abort
ADOP-Revoke & Abort Process in R12.2
Here are steps to Abort an Online Patching Cycle
$ adop phase=prepare
$ adop phase=apply patches=9999999
$ adop phase=abort
$ adop phase=cleanup cleanup_mode=full
$ adop phase=fs_clone
Identify and fix any other issues in the current patching cycle, and proceed with patching.
*********************************************************************************************8
2. How to rollback the patch after failed cutover phase in R12.2
If you had not run the cutover phase, you would have been able to roll back the patch application process by running the adop abort phase. However, this is not possible once cutover has been run.
There are two main parts to rollback the patch:
1) Database Restore
- Flashback database is the fastest method to rollback the database changes and go back to point in time.
- We can use database restore technique also but that is very time consuming
SQL>shutdown immediate
SQL>startup mount
SQL>flashback database to time to_data(;
SQL>alter database open read only;
Check all looks as expected.
SQL>shutdown immediate
SQL>startup mount
SQL>alter database open resetlogs;
2) Filesystem restore
- Depending on when cutover failed, you may also need to restore the application tier file systems by referring to the cutover logs in $NE_BASE/EBSapps/log/adop//cutover_/ for your current session id.
Case 1 – If the log messages indicate that cutover failed before the file systems were switched, do a clean shutdown of any services that are running. Then restart all the services using the normal startup script,
Case 2 – If the log messages indicate that cutover failed after the file systems were switched, then follow below step to switch the file systems back.
- a) Shut down services started from new run file system
- b)In a multi-node environment, repeat the preceding two steps on all nodes, leaving the admin node until after all the slave nodes.
- c) Switch file systems back
1.On all nodes where file systems have been switched, run the following command to switch the file systems back:
$ perl $AD_TOP/patch/115/bin/txkADOPCutOverPhaseCtrlScript.pl
-action=ctxupdate
-contextfile=
-patchcontextfile=
-outdir=
- d)Start up all services from the old run file system (using adstrtal.sh on UNIX).
- e)In a multi-node environment, repeat the preceding two steps on all nodes, starting with the admin node and then proceeding to the slave nodes
SELECT adb.bug_number,ad_patch.is_patch_applied('R12', -1, adb.bug_number)
FROM ad_bugs adb
WHERE adb.bug_number in (21900871);
******************************************************************************************************************8
2. ADOP Options: actualize_all
Whenever adop prepare phase is initiated, a new patch edition is created in the database.During Online patching (ADOP) : An additional column ZD_EDITION_NAME is populated in the seed tables.As we do more online patching cycles, the number of entries for database editions will increase. This affects system performance and also increases cleanup time.When the number of old database editions reaches 25 or more, you should consider dropping all old database editions by running the adop actualize_all phase and then performing a full cleanup.
$ adop phase=prepare
$ adop phase=actualize_all
$ adop phase=finalize finalize_mode=full
$ adop phase=cutover
$ adop phase=cleanup cleanup_mode=full
*************************************************************8
3. Adop Prepare Vs Fs_Clone :
Key Point: Prepare just Check run file system to Patch filesystem.
Fs_Clone adop patch filesystem and copy run filesystem to patch filesystem.
Checks that the environment is set to the run APPL_TOP. Checks whether to perform a cleanup, which will be needed if the user failed to invoke cleanup after the cutover phase of a previous online patching cycle.
Checks to see if the database is prepared for online patching:Checks that the FILE_EDITION environment variable value is set to ‘run Checks to see if enough space is available in the database (SYSTEM tablespace should have minimum of 25 GB of free space and APPS_TS_SEED tablespace should have minimum of 5 GB of free space)
Checks the file system, using the TXK script $AD_TOP/patch/115/bin/txkADOPPreparePhaseSanityCheck.pl. This script checks for the file system space, database connections, Apps/System/Weblogic Passwords, Contextfile Validation and so on
Produces a report showing information about the most important tablespaces is generated. This report is created in $APPL_TOP/admin/$TWO_TASK/out.
Checks for the existence of the “Online Patching In Progress” (ADZDPATCH) concurrent program. This program prevents certain predefined concurrent programs from being started, and as such needs to be active while a patching cycle is in progress.
Invokes the TXK script $AD_TOP/patch/115/bin/txkADOPPreparePhaseSynchronize.pl to synchronize the patches which have been applied to the run appltop.
Checks the database for the existence of a patch edition, and creates one if it does not find one
A patch edition is created in the database.
All code objects in the patch edition begin as pointers to code objects in the run edition. Code objects in the patch edition begin as lightweight “stub objects” that point to the actual object definitions, which are inherited from earlier editions. Stub objects consume minimal space, so the database patch edition is initially very small in size.
As patches are applied to the patch edition, code objects are actualized (have a new definition created) in that edition.
9. Calls the $AD_TOP/patch/115/bin/txkADOPPreparePhaseSanityCheck.pl script again to confirm that the database connection to the patch edition is working.
B) adop FS_CLONE PHASE DETAILS, What it will do:
The fs_clone phase is a command (not related to adcfgclone.pl) that is used to synchronize the patch file system with the run file system. The fs_clone phase should only be run when mentioned as part of a specific documented procedure.
This phase is useful if the APPL_TOPs have become very unsynchronized (meaning that there would be a large number of delta patches to apply). It is a heavyweight process, taking a backup of the entire current patch APPL_TOP and then cloning the run APPL_TOP to create a new patch APPL_TOP. As this method requires more time and disk space, it should only be used when the state of the patch file system is unknown. This command must be invoked from the run file system, before the next prepare phase is run.
******************************************************************8
Important stuff on R12.2
===========================
Adop uses SID_patch service_name to connect to database
2) Adop Connects to other nodes in multinodes setup via ssh and applies the patch ( similar to RAC patchings).It is executed by user on master node.
It is important to enable the ssh from master node to other nodes
If a node unexpectedly becomes inaccessible via ssh, it will be abandoned by adop, and the appropriate further actions taken. Consider a scenario where the adop phase=prepare command is run in a system with ten application tier nodes. The command is successful on nine nodes, but fails on the tenth. In such a case, adop will identify the services enabled on nodes 1-9. If they are sufficient for Oracle E-Business Suite to continue to run normally, adop will mark node 10 as abandoned and then proceed with its patching actions. If they are not sufficient, adop will proceed no further.
3) How to find Oracle EBS Weblogic Server Admin Port Number and URL
Web Logic Server Admin Port
Method 1:
Open the EBS domain config file in following location.
$EBS_DOMAIN_HOME/config/config.xml
Then check for Admin Server Port.
Method 2:
Open the application tier context file
$CONTEXT_FILE
Then check the value of variable “s_wls_adminport” in the for the correct Web Logic Server Admin port number
3. Web Logic Server Console URL
http://<server name>. <domain name> : < WLS Admin Port>/console
Home » Oracle » Important stuff about R12.2
Important stuff about R12.2
May 25, 2016 by techgoeasy Leave a Comment
FacebookTwitterEmailCopy LinkMore
Important stuff on R12.2
Adop uses SID_patch service_name to connect to database
2) Adop Connects to other nodes in multinodes setup via ssh and applies the patch ( similar to RAC patchings).It is executed by user on master node.
It is important to enable the ssh from master node to other nodes
If a node unexpectedly becomes inaccessible via ssh, it will be abandoned by adop, and the appropriate further actions taken. Consider a scenario where the adop phase=prepare command is run in a system with ten application tier nodes. The command is successful on nine nodes, but fails on the tenth. In such a case, adop will identify the services enabled on nodes 1-9. If they are sufficient for Oracle E-Business Suite to continue to run normally, adop will mark node 10 as abandoned and then proceed with its patching actions. If they are not sufficient, adop will proceed no further.
3) How to find Oracle EBS Weblogic Server Admin Port Number and URL
Web Logic Server Admin Port
Method 1:
Open the EBS domain config file in following location.
$EBS_DOMAIN_HOME/config/config.xml
Then check for Admin Server Port.
Method 2:
Open the application tier context file
$CONTEXT_FILE
Then check the value of variable “s_wls_adminport” in the for the correct Web Logic Server Admin port number
Web Logic Server Console URL
http://<server name>. <domain name> : < WLS Admin Port>/console
4) Important new variable in R12.2
$FILE_EDITION shows which file edition you are using, run or patch
$RUN_BASE shows absolute path to run file system
$PATCH_BASE shows absolute path to patch file system
$NE_BASE shows absolute path to non-edition file system
$APPL_TOP_NE non-editioned appl_top path. Equivalent to $NE_BASE/EBSapps/appl
$LOG_HOME Application Instance Specific Log Directory
$ADOP_LOG_HOME Online patching Specific Log Directory. Equivalent to $NE_BASE/EBSapps/log/adop
$IAS_ORACLE_HOME FMW Web Tier Home Directory
$ORACLE_HOME 10.1.2 ORACLE_HOME
$CONTEXT_FILE Source for information populating template files (autoconfig)
$EBS_DOMAIN_HOME WLS Deployment of Oracle E-Business Suite 12.2 Domain (instance specific
$ADMIN_SCRIPTS_HOME Shell scripts to control processes associated to the Applications Instance
$EBS_ORACLE_HOME Oracle E-Business Suite 12.2 FMW Deployment directory
$RW 10.1.2 reports directory
$APPS_VERSION to get the EBS version
*****************************************************************************************************
Adop phases and parameters:
Adop phases
1) prepare - Starts a new patching cycle.
Usage: adop phase=prepare
2) Apply - Used to apply a patch to the patch file system (online mode)
Usage: adop phase= apply patches = <>
Optional parameters during apply phase
--> input file : adop accepts parameters in a input file
adop phase=apply input_file=
Input file can contain the following parameter:
workers=
patches=:.drv, :.drv ...
adop phase=apply input_file=input_file
patches
phase
patchtop
merge
defaultsfile
abandon
restart
workers
Note : Always specify the full path to the input file
--> restart -- used to resume a failed patch
adop phase=apply patches=<> restart=yes
--> abandon -- starts the failed patch from scratch
adop phase=apply patches=<> abandon=yes
--> apply_mode
adop phase=apply patches=<> apply_mode=downtime
Use apply_mode=downtime to apply the patch in downtime mode ( in this case,patch is applied on run file system)
--> apply=(yes/no)
To run the patch test mode, specify apply = no
--> analytics
adop phase=apply analytics=yes
Specifying this option will cause adop to run the following scripts and generate the associated output files (reports):
ADZDCMPED.sql - This script is used to display the differences between the run and patch editions, including new and changed objects.
The output file location is: /u01/R122_EBS/fs_ne/EBSapps/log/adop////adzdcmped.out.
ADZDSHOWED.sql - This script is used to display the editions in the system.
The output file location is: /u01/R122_EBS/fs_ne/EBSapps/log/adop///adzdshowed.out.
ADZDSHOWOBJS.sql - This script is used to display the summary of editioned objects per edition.
The output file location is: /u01/R122_EBS/fs_ne/EBSapps/log/adop///adzdshowobjs.out
ADZDSHOWSM.sql - This script is used to display the status report for the seed data manager.
The output file location is: /u01/R122_EBS/fs_ne/EBSapps/log/adop///adzdshowsm.out
3) Finalize : Performs any final steps required to make the system ready for cutover.. invalid objects are compiled in this phase
Usage: adop phase=finalize
finalize_mode=(full|quick)
4) Cutover : A new run file system is prepared from the existing patch file system.
adop phase=cutover
Optional parameters during cutover phase:
-->mtrestart - With this parameter, cutover will complete without restarting the application tier services
adop phase=cutover mtrestart=no
-->cm_wait - Can be used to specify how long to wait for existing concurrent processes to finish running before shutting down the Internal Concurrent Manager.
By default, adop will wait indefinitely for in-progress concurrent requests to finish.
5) CLEANUP
cleanup_mode=(full|standard|quick) [default: standard]
6) FS_CLONE : This phase syncs the patch file system with the run file system.
Note : Prepare phase internally runs fs_clone if it is not run in the previous patching cycle
Optional parameters during fs_clone phase:
i ) force - To start a failed fs_clone from scratch
adop phase=fs_clone force=yes [default: no]
ii ) Patch File System Backup Count ==> s_fs_backup_count [default: 0 : No backup taken]
Denotes the number of backups of the patch file system that are to be preserved by adop. The variable is used during the fs_clone phase,
where the existing patch file system is backed up before it is recreated from the run file system.
7) Abort - used to abort the current patching cylce.
abort can be run only before the cutover phase
adop phase=abort
ADOP-Revoke & Abort Process in R12.2
Here are steps to Abort an Online Patching Cycle
$ adop phase=prepare
$ adop phase=apply patches=9999999
$ adop phase=abort
$ adop phase=cleanup cleanup_mode=full
$ adop phase=fs_clone
Identify and fix any other issues in the current patching cycle, and proceed with patching.
*********************************************************************************************8
2. How to rollback the patch after failed cutover phase in R12.2
If you had not run the cutover phase, you would have been able to roll back the patch application process by running the adop abort phase. However, this is not possible once cutover has been run.
There are two main parts to rollback the patch:
1) Database Restore
- Flashback database is the fastest method to rollback the database changes and go back to point in time.
- We can use database restore technique also but that is very time consuming
SQL>shutdown immediate
SQL>startup mount
SQL>flashback database to time to_data(;
SQL>alter database open read only;
Check all looks as expected.
SQL>shutdown immediate
SQL>startup mount
SQL>alter database open resetlogs;
2) Filesystem restore
- Depending on when cutover failed, you may also need to restore the application tier file systems by referring to the cutover logs in $NE_BASE/EBSapps/log/adop//cutover_/ for your current session id.
Case 1 – If the log messages indicate that cutover failed before the file systems were switched, do a clean shutdown of any services that are running. Then restart all the services using the normal startup script,
Case 2 – If the log messages indicate that cutover failed after the file systems were switched, then follow below step to switch the file systems back.
- a) Shut down services started from new run file system
- b)In a multi-node environment, repeat the preceding two steps on all nodes, leaving the admin node until after all the slave nodes.
- c) Switch file systems back
1.On all nodes where file systems have been switched, run the following command to switch the file systems back:
$ perl $AD_TOP/patch/115/bin/txkADOPCutOverPhaseCtrlScript.pl
-action=ctxupdate
-contextfile=
-patchcontextfile=
-outdir=
- d)Start up all services from the old run file system (using adstrtal.sh on UNIX).
- e)In a multi-node environment, repeat the preceding two steps on all nodes, starting with the admin node and then proceeding to the slave nodes
SELECT adb.bug_number,ad_patch.is_patch_applied('R12', -1, adb.bug_number)
FROM ad_bugs adb
WHERE adb.bug_number in (21900871);
******************************************************************************************************************8
2. ADOP Options: actualize_all
Whenever adop prepare phase is initiated, a new patch edition is created in the database.During Online patching (ADOP) : An additional column ZD_EDITION_NAME is populated in the seed tables.As we do more online patching cycles, the number of entries for database editions will increase. This affects system performance and also increases cleanup time.When the number of old database editions reaches 25 or more, you should consider dropping all old database editions by running the adop actualize_all phase and then performing a full cleanup.
$ adop phase=prepare
$ adop phase=actualize_all
$ adop phase=finalize finalize_mode=full
$ adop phase=cutover
$ adop phase=cleanup cleanup_mode=full
*************************************************************8
3. Adop Prepare Vs Fs_Clone :
Key Point: Prepare just Check run file system to Patch filesystem.
Fs_Clone adop patch filesystem and copy run filesystem to patch filesystem.
Checks that the environment is set to the run APPL_TOP. Checks whether to perform a cleanup, which will be needed if the user failed to invoke cleanup after the cutover phase of a previous online patching cycle.
Checks to see if the database is prepared for online patching:Checks that the FILE_EDITION environment variable value is set to ‘run Checks to see if enough space is available in the database (SYSTEM tablespace should have minimum of 25 GB of free space and APPS_TS_SEED tablespace should have minimum of 5 GB of free space)
Checks the file system, using the TXK script $AD_TOP/patch/115/bin/txkADOPPreparePhaseSanityCheck.pl. This script checks for the file system space, database connections, Apps/System/Weblogic Passwords, Contextfile Validation and so on
Produces a report showing information about the most important tablespaces is generated. This report is created in $APPL_TOP/admin/$TWO_TASK/out.
Checks for the existence of the “Online Patching In Progress” (ADZDPATCH) concurrent program. This program prevents certain predefined concurrent programs from being started, and as such needs to be active while a patching cycle is in progress.
Invokes the TXK script $AD_TOP/patch/115/bin/txkADOPPreparePhaseSynchronize.pl to synchronize the patches which have been applied to the run appltop.
Checks the database for the existence of a patch edition, and creates one if it does not find one
A patch edition is created in the database.
All code objects in the patch edition begin as pointers to code objects in the run edition. Code objects in the patch edition begin as lightweight “stub objects” that point to the actual object definitions, which are inherited from earlier editions. Stub objects consume minimal space, so the database patch edition is initially very small in size.
As patches are applied to the patch edition, code objects are actualized (have a new definition created) in that edition.
9. Calls the $AD_TOP/patch/115/bin/txkADOPPreparePhaseSanityCheck.pl script again to confirm that the database connection to the patch edition is working.
B) adop FS_CLONE PHASE DETAILS, What it will do:
The fs_clone phase is a command (not related to adcfgclone.pl) that is used to synchronize the patch file system with the run file system. The fs_clone phase should only be run when mentioned as part of a specific documented procedure.
This phase is useful if the APPL_TOPs have become very unsynchronized (meaning that there would be a large number of delta patches to apply). It is a heavyweight process, taking a backup of the entire current patch APPL_TOP and then cloning the run APPL_TOP to create a new patch APPL_TOP. As this method requires more time and disk space, it should only be used when the state of the patch file system is unknown. This command must be invoked from the run file system, before the next prepare phase is run.
******************************************************************8
Important stuff on R12.2
===========================
Adop uses SID_patch service_name to connect to database
2) Adop Connects to other nodes in multinodes setup via ssh and applies the patch ( similar to RAC patchings).It is executed by user on master node.
It is important to enable the ssh from master node to other nodes
If a node unexpectedly becomes inaccessible via ssh, it will be abandoned by adop, and the appropriate further actions taken. Consider a scenario where the adop phase=prepare command is run in a system with ten application tier nodes. The command is successful on nine nodes, but fails on the tenth. In such a case, adop will identify the services enabled on nodes 1-9. If they are sufficient for Oracle E-Business Suite to continue to run normally, adop will mark node 10 as abandoned and then proceed with its patching actions. If they are not sufficient, adop will proceed no further.
3) How to find Oracle EBS Weblogic Server Admin Port Number and URL
Web Logic Server Admin Port
Method 1:
Open the EBS domain config file in following location.
$EBS_DOMAIN_HOME/config/config.xml
Then check for Admin Server Port.
Method 2:
Open the application tier context file
$CONTEXT_FILE
Then check the value of variable “s_wls_adminport” in the for the correct Web Logic Server Admin port number
3. Web Logic Server Console URL
http://<server name>. <domain name> : < WLS Admin Port>/console
Home » Oracle » Important stuff about R12.2
Important stuff about R12.2
May 25, 2016 by techgoeasy Leave a Comment
FacebookTwitterEmailCopy LinkMore
Important stuff on R12.2
Adop uses SID_patch service_name to connect to database
2) Adop Connects to other nodes in multinodes setup via ssh and applies the patch ( similar to RAC patchings).It is executed by user on master node.
It is important to enable the ssh from master node to other nodes
If a node unexpectedly becomes inaccessible via ssh, it will be abandoned by adop, and the appropriate further actions taken. Consider a scenario where the adop phase=prepare command is run in a system with ten application tier nodes. The command is successful on nine nodes, but fails on the tenth. In such a case, adop will identify the services enabled on nodes 1-9. If they are sufficient for Oracle E-Business Suite to continue to run normally, adop will mark node 10 as abandoned and then proceed with its patching actions. If they are not sufficient, adop will proceed no further.
3) How to find Oracle EBS Weblogic Server Admin Port Number and URL
Web Logic Server Admin Port
Method 1:
Open the EBS domain config file in following location.
$EBS_DOMAIN_HOME/config/config.xml
Then check for Admin Server Port.
Method 2:
Open the application tier context file
$CONTEXT_FILE
Then check the value of variable “s_wls_adminport” in the for the correct Web Logic Server Admin port number
Web Logic Server Console URL
http://<server name>. <domain name> : < WLS Admin Port>/console
4) Important new variable in R12.2
$FILE_EDITION shows which file edition you are using, run or patch
$RUN_BASE shows absolute path to run file system
$PATCH_BASE shows absolute path to patch file system
$NE_BASE shows absolute path to non-edition file system
$APPL_TOP_NE non-editioned appl_top path. Equivalent to $NE_BASE/EBSapps/appl
$LOG_HOME Application Instance Specific Log Directory
$ADOP_LOG_HOME Online patching Specific Log Directory. Equivalent to $NE_BASE/EBSapps/log/adop
$IAS_ORACLE_HOME FMW Web Tier Home Directory
$ORACLE_HOME 10.1.2 ORACLE_HOME
$CONTEXT_FILE Source for information populating template files (autoconfig)
$EBS_DOMAIN_HOME WLS Deployment of Oracle E-Business Suite 12.2 Domain (instance specific
$ADMIN_SCRIPTS_HOME Shell scripts to control processes associated to the Applications Instance
$EBS_ORACLE_HOME Oracle E-Business Suite 12.2 FMW Deployment directory
$RW 10.1.2 reports directory
$APPS_VERSION to get the EBS version
*****************************************************************************************************
Oracle Apps R12.2 Log Files Location
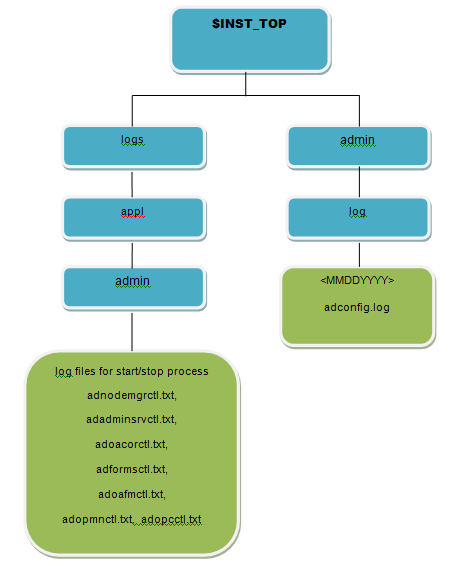
1. R12.2 Start/Stop Log Files:$INST_TOP/logs/appl/admin/log
Logfiles for start/stop of services from $ADMIN_SCRIPTS_HOME
Logfiles for start/stop of services from $ADMIN_SCRIPTS_HOME
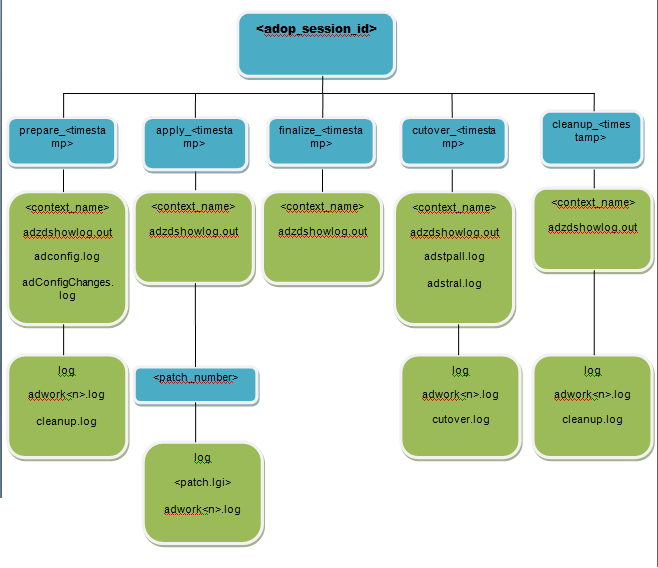
Here is an image representing EBS R12.2 Service control (start/stop) logs:
Green colour boxes indicates location of log files
Green colour boxes indicates location of log files
2. Patching log files
a) Online patching files are located in on the non-editioned file system(fs_ne) under:
$NE_BASE/ EBSapps/log/adop/<adop_session_id>/<phase>_<date>_<time>/<context_name>/log
3. Log files for concurrent programs/managers
$NE_BASE/ inst/<CONTEXT_NAME>/logs/appl/conc/log
Output files for concurrent programs/managers$NE_BASE/inst/<CONTEXT_NAME>/logs/appl/conc/out
a) Online patching files are located in on the non-editioned file system(fs_ne) under:
$NE_BASE/ EBSapps/log/adop/<adop_session_id>/<phase>_<date>_<time>/<context_name>/log
3. Log files for concurrent programs/managers
$NE_BASE/ inst/<CONTEXT_NAME>/logs/appl/conc/log
Output files for concurrent programs/managers$NE_BASE/inst/<CONTEXT_NAME>/logs/appl/conc/out
Here is an image representing EBS R12.2 Non-Editioned file system Logs:
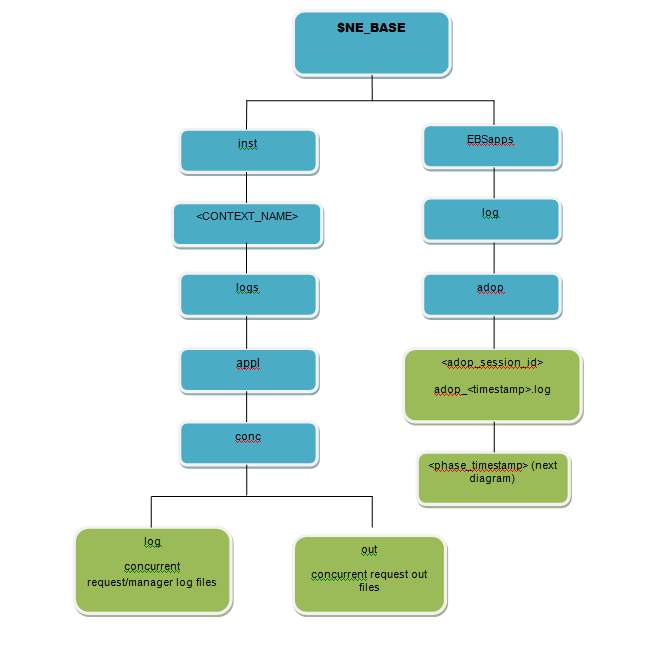
Patching Log file location:
4. Cloning related Log files:
a) Pre-clone log files in source instance
I. Database Tier
$ORACLE_HOME/appsutil/log/$CONTEXT_NAME/(StageDBTier_MMDDHHMM.log)
$ORACLE_HOME/appsutil/log/$CONTEXT_NAME/(StageDBTier_MMDDHHMM.log)
II. Application Tier$INST_TOP/admin/log/ (StageAppsTier_MMDDHHMM.log)
b) Clone log files in target instance
I. Database Tier$ORACLE_HOME/appsutil/log/$CONTEXT_NAME/ApplyDBTier_<time>.log
II. Apps Tier
$INST_TOP/admin/log/ApplyAppsTier_<time>.log
$INST_TOP/admin/log/ApplyAppsTier_<time>.log
Known issues:
Clone DB Tier fails while running txkConfigDBOcm.pl (Check metalink note – 415020.1)
During clone step on DB Tier it prompts for “Target System base directory for source homes” and during this you have to give like /base_install_dir like ../../r12 and not oracle home like ../../r12/db/tech_st_10.2.0
Clone DB Tier fails while running txkConfigDBOcm.pl (Check metalink note – 415020.1)
During clone step on DB Tier it prompts for “Target System base directory for source homes” and during this you have to give like /base_install_dir like ../../r12 and not oracle home like ../../r12/db/tech_st_10.2.0
5. AutoConfig log file:
a) Autoconfig log location on application tier:$INST_TOP/admin/log/$MMDDHHMM/adconfig.log
a) Autoconfig log location on application tier:$INST_TOP/admin/log/$MMDDHHMM/adconfig.log
b) Autoconfig Log Location on Database tier:
$ORACLE_HOME/ appsutil/ log/ $CONTEXT_NAME/ <MMDDHHMM>/ *.log
$ORACLE_HOME/ appsutil/ log/ $CONTEXT_NAME/ <MMDDHHMM>/ *.log
6. Installation Related Logs:
Four Phases of R12.2 installation
1) RapidWiz Configuration file saved in below locations:
$TMP/<MMDDHHMM>/conf_<SID>.txt
$INST_TOP/conf_<SID>.txt
<RDBMS ORACLE_HOME>/ appsutil/ conf_<SID>.txt
1) RapidWiz Configuration file saved in below locations:
$TMP/<MMDDHHMM>/conf_<SID>.txt
$INST_TOP/conf_<SID>.txt
<RDBMS ORACLE_HOME>/ appsutil/ conf_<SID>.txt
2) Pre-install system check logs:
$TMP/<MMDDHHMM>/<MMDDHHMM>.log
$TMP/dbPreInstCheck.xxxxx.log
$TMP/wtprechk.xxxx/wtprechk.xxxx.log
<Global Inventory>/logs/installActions<timestamp>.log
$TMP/<MMDDHHMM>/<MMDDHHMM>.log
$TMP/dbPreInstCheck.xxxxx.log
$TMP/wtprechk.xxxx/wtprechk.xxxx.log
<Global Inventory>/logs/installActions<timestamp>.log
3) Database Tier logs:
a) Main installation logs:
RDBMS $ORACLE_HOME/ appsutil/ log/ $CONTEXT_NAME/ <MMDDHHMM>.log
a) Main installation logs:
RDBMS $ORACLE_HOME/ appsutil/ log/ $CONTEXT_NAME/ <MMDDHHMM>.log
b) ORACLE_HOME installation logs:
RDBMS $ORACLE_HOME/ temp/ $CONTEXT_NAME/ logs/ *.log
<Global Inventory>/logs/*.log
RDBMS $ORACLE_HOME/ temp/ $CONTEXT_NAME/ logs/ *.log
<Global Inventory>/logs/*.log
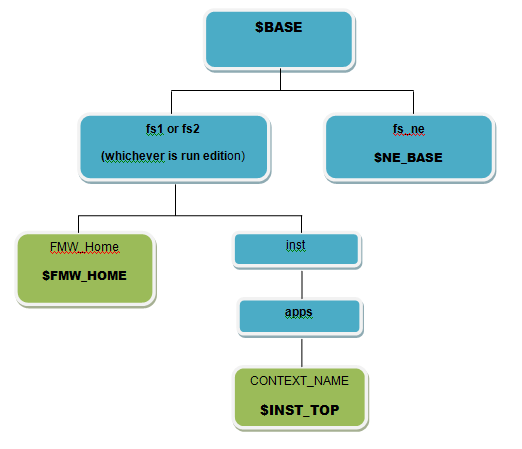
d) Application tier
Both primary(Run) and Secondary Edition (Patch) file systems will each contain these logs:
1. Main Installation logs:
$INST_TOP/logs/<MMDDHHMM>.log
Both primary(Run) and Secondary Edition (Patch) file systems will each contain these logs:
1. Main Installation logs:
$INST_TOP/logs/<MMDDHHMM>.log
2. FMW and OHS TechStack Installation/Patching logs:
$APPL_TOP/admin/$CONTEXT_NAME/log/*<Global Inventory>/logs/*.log
$APPL_TOP/admin/$CONTEXT_NAME/log/*<Global Inventory>/logs/*.log
3.Forms Oracle Home installation logs:
$APPL_TOP/admin/$CONTEXT_NAME/log/*.log
$APPL_TOP/admin/$CONTEXT_NAME/log/*.log
Here is an image representing the R12.2 Installation logs,
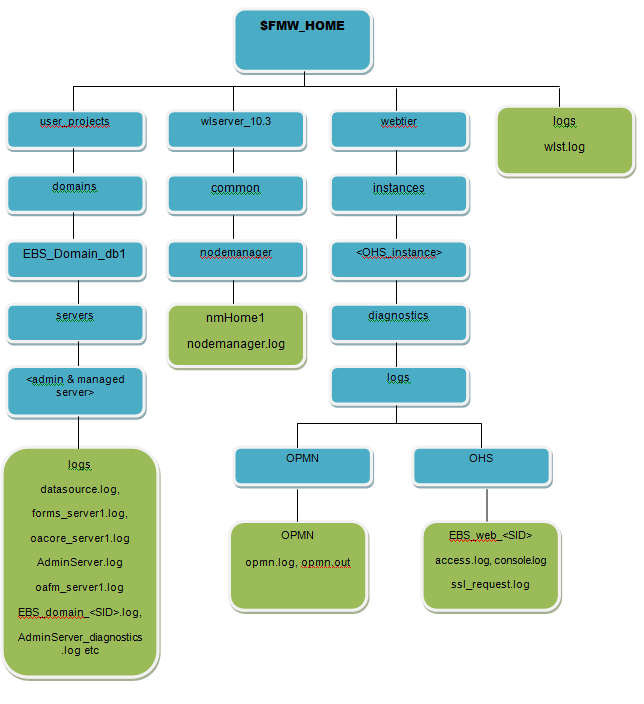
6. Fusion Middleware (FMW_HOME) Log Files:
a) Log files for OPMN and OHS processes: Below directory contains log files related OPMN process(opmn.log), OPMN Debug logs(debug.log), HTTP Transaction logs (access.log), security settings related logs.
$IAS_ORACLE_HOME/ instances/ <ohs_instance>/diagnostics/logs
b) Log files for weblogic node manager: Log file is generated by Node Manager and contains data for all domains that are controlled by Node Manager on a given physical machine.
$FMW_HOME/ wlserver_10.3/ common/ nodemanager/ nmHome1/ nodemanager.log
c) Log files for weblogic Oracle Management Service log file: Initial settings AdminServer and Domain level information is written in this log file.
$EBS_DOMAIN_HOME/sysman/log
$EBS_DOMAIN_HOME/sysman/log
d) Log files for server processes initiated through weblogic: Stdout and stderr messages generated by the server instance (server instances like forms, oafm, oacore etc) at NOTICE severity level or higher are written by Weblogic Node Manager to below directory.
$EBS_DOMAIN_HOME/ servers/ <server_name>/ logs/ <server_name>.out
$EBS_DOMAIN_HOME/ servers/ <server_name>/ logs/ <server_name>.out
Here is an image representing EBS R12.2 Fusion Middleware Log files:
4. config.xml location.
cd $COMMON_TOP/admin/scripts/<context_name>/
*************************************************
5. FNDFS and FNDSM in Oracle R12:
==============================
FNDFS or the Report Review Agent (RRA) is the default text viewer within Oracle Applications, which allows users to view report output and log files. Report Review Agent is also referred to by the executable FNDFS. The default viewer must be configured correctly before external editors or browsers are used for viewing requests.
FNDSM is the Service manager. FNDSM is executable & core component in GSM ( Generic Service Management Framework ). You start FNDSM services via APPS listener on all Nodes in Application Tier.
There are certain scenario where we can't see the output of Concurrent Requests. It just gives an error.
Then check the fndwrr.exe size in production and compare it with Test Instance.
fndwrr.exe is present in $FND_TOP/bin
If there is any difference then relink the FNDFS executable.It might not be in sync with the binaries.
Command for relinking
adrelink.sh force=y "fnd FNDFS"
****************************************************************
6. Troubleshooting EBS 12.2 login page errors
EBS login flow and importance of users such as GUEST, APPS and APPLSYS. In this post we will see what to look for when we face some issues while accessing the EBS login page.
Troubleshooting EBS login page issue
1. If the login page doesn't comes up then we have to focus on the varios logs present under $LOG_HOME directory. In case of EBS 12.2(as it is the latest release),
1) OHS (apache) failure
If OHS is not running or not responding, one would see a message as below. If OHS is not running then there will not be any messages in any EBS log file for this request.
Firefox: “The connection was reset”
Steps to take
Check OHS has started OK
adapcctl.sh status
adapcctl.sh stop
adapcctl.sh start
2 OACore JVM process not available
If the OACore JVM is not running or not reachable, then one will likely see the following message in the browser:
Failure of server APACHE bridge:
No backend server available for connection: timed out after 10 seconds or idempotent set to OFF or method not idempotent.
There could be two reason
Steps to take
a)Make sure the OACore JVM has started correctly
admanagedsrvctl.sh start oacore
b) Check mod_wl_ohs.conf file is configured correctly
3) oacore J2EE application not available
There may be cases where the OACore JVM is running and reachable but the oacore application is not available.
The browser will report the error:
Error 404–Not Found
From RFC 2068 Hypertext Transfer Protocol — HTTP/1.1:
10.4.5 404 Not Found
The server has not found anything matching the Request-URI. No indication is given of whether the condition is temporary or permanent.
Access_log will show 404 error:
GET /OA_HTML/AppsLogin HTTP/1.1″ 404
Steps to take
In the FMW Console check the “deployments” to confirm the “oacore” application is at status “Active” and Health is “OK”.
4) Datasource failure
The oacore logs will show this type of error
<Error> <ServletContext-/OA_HTML> <BEA-000000> <Logging call failed exception::
java.lang.NullPointerException
at oracle.apps.fnd.sso.AppsLoginRedirect.logSafe(AppsLoginRedirect.java:639)
at oracle.apps.fnd.sso.AppsLoginRedirect.doGet(AppsLoginRedirect.java:1314)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:707)
The explorer will show
The system has encountered an error while processing your request.Please contact your system administrator
Steps to Take
Review the EBS Datasource and make sure it is targeted to the oacore_cluster1 managed server. Also use the “Test Datasource” option to confirm database connection can be made
If one makes any changes, one will need to restart the managed server.
Once we get the ebs login page and upon passing the credentials, if we are not getting the home page then we should focus on
1. Check the OHS files and see if they are correct or not
2. APPL_SERVER_ID in dbc file matches with server ID in FND_NODES table against respective Server
3. GUEST/ORACLE password is correct & user is not end dated
4. APPS and APPlSYS password should be same
*********************************************************************************
Check Value in DBC File
[test appl]$ grep -i GUEST_USER_PWD $FND_SECURE/visr12.dbc
GUEST_USER_PWD=GUEST/ORACLE
Check profile option value in DB
[test appl]$ sqlplus apps/
SQL> select fnd_profile.value('GUEST_USER_PWD') from dual;
FND_PROFILE.VALUE(’GUEST_USER_PWD’)
——————————————————————————–
GUEST/ORACLE
Value for step 1 and 2 must be sync
Guest user connectivity check
SQL> select FND_WEB_SEC.VALIDATE_LOGIN('GUEST','ORACLE') from dual;
FND_WEB_SEC.VALIDATE_LOGIN('GUEST','ORACLE')
——————————————————————————–-----
Y
proper configuration should return it as Y
4. Compile JSP
[test appl]$ cd $FND_TOP/patch/115/bin
[test bin]$ ojspCompile.pl --compile --flush
**************************************************************************************************
5. There is JSP tool test to find most of issues via
http://host.domain:port/OA_HTML/jsp/fnd/aoljtest.jsp
Reference: 12.2 E-Business Suite Technology Stack Summary Of The iAS / HTTP Server Login Process And What To Expect When One Of The Login Components Fails (Doc ID 1984710.1)
******************************************************************************************************************888888888888******************
7. Java Forms opening issue in EBS (R12):
let’s first understand about Oracle Forms, it can be configured in two modes: servlet and socket.
In servlet mode, a Java servlet (called the Forms Listener servlet) manages the communication between the Forms Java client and the OracleAS Forms services. In socket mode, the desktop
clients access the Forms server directly.
To know more about Oracle Forms check our post Oracle Apps R12 Forms: Servlet or Socket
Issue:
We were trying to access System Administrator -> Define Profile Options but Java plugins were not working due to which forms are not opening:
Fix: clinet desktop.
1. Copy the URL that you are unable to open. In our case 1704ebs54.k21technologies.com:8000
2. Open Control panel, then search for Java and click on that.
3. Click on Security
4. Click the “Edit Site List…”
5. 5. Click on Add and Paste the URL into the “Location” text box then click OK
7. Click OK on Java Control Panel and reload the page
****************************************************************************************************************************************************
8. About Oracle Application Framework in EBS:
=========================================
Oracle Application Framework (OAF) is an architecture for creating web based front end pages and J2EE type of applications within the Oracle EBS ERP platform.Oracle Application Framework is
the development and deployment platform developed by Oracle to develop the Oracle E-Business Suite “Self-Service” or HTML based Applications.
II). Concurrent Program:
How to Tune Concurrent Manager?
++++++++++++++++++++++++++++++++
There are 5 ways to faster your CM
1.PMON cycle, queue size, and sleep time.
2.Purging Concurrent Requests
3.Adjusting the Concurrent Manager Cache Size
4.Analyzing Oracle Apps Dictionary Tables for High Performance
5. Number of Standard Managers
1.PMON cycle, queue size, and sleep time.
The ICM performance is affected by the three important Oracle parameters
PMON cycle
This is the number of sleep cycles that the ICM waits between the time it checks for concurrent managers failures, are having problems with abnormal terminations.
Queue Size
The queue size is the number of PMON cycles that the ICM waits between checking for disabled or new concurrent managers. The default for queue size of 1 PMON cycle should be used.
Sleep Time
The sleep time parameter indicates the seconds that the ICM should wait between checking for requests that are waiting to run. The default sleep time is 60, but you can lower this number if
you see you have a lot of request waiting (Pending/Normal). However, reducing this number to a very low value many cause excessive cpu utilization.
2.Purging Concurrent Requests
One important area of Concurrent Manager tuning is monitoring the space usage for the subsets within each concurrent manager.
When the space in FND_CONCURRENT_PROCESSES and FND_CONCURRENT_REQUESTS exceed 50K, you can start to experience serious performance problems within your Oracle Applications. When you
experience these space problems, a specific request called “Purge Concurrent Requests And/Or Manager Data” should be scheduled to run on a regular basis. This request can be configured to
purge the request data from the FND tables as well as the log files and output files on accumulate on disk.
3.Adjusting the Concurrent Manager Cache Size
Concurrent manager performance can also be enhanced by increasing the manager cache size to be at lease twice the number of target processes. The cache size specifies the number of requests
that will be cached each time the concurrent manager reads from the FND_CONCURRENT_REQUESTS table. Increasing the cache size will boost the throughput of the managers by attempting to avoid
sleep time.
4.Analyzing Oracle Apps Dictionary Tables for High Performance
We can generate statistics that quantify the data distribution and storage characteristics of tables, columns,indexes, and partitions. The cost-based optimization approach uses these
statistics to calculate the selectivity of predicates and to estimate the cost of each execution plan. Selectivity is the fraction of rows in a table that the SQL statement’s predicate
chooses. The optimizer uses the selectivity of a predicate to estimate the cost of a particular access method and to determine the optimal join order and join method.
We should gather statistics periodically for objects where the statistics become stale over time because of changing data volumes or changes in column values. New statistics should be
gathered after a schema object’s data or structure are modified in ways that make the previous statistics inaccurate. For example, after loading a significant number of rows
into a table, collect new statistics on the number of rows. After updating data in a table, you do not need to collect new statistics on the number of rows, but you might need new statistics
on the average row length.
It is also very important to run the request Gather Table Statistics on these tables:
FND_CONCURRENT_PROCESSES
FND_CONCURRENT_PROGRAMS
FND_CONCURRENT_REQUESTS
FND_CONCURRENT_QUEUES.
5. Number of Standard Managers
Some of environments are copies of other environments, and you may find that the number of Standard Concurrent Managers are just 5. You can increase this to say 10 or 15, this will help the
pending requests queue is not getting too long & the Conflict Resolution Manager will have less load
********************************************************************************************************
2. Long running concurrent Program Suppose it DB side Issue:
============================================================
1. Sanity checks
Top Free -g
Check alert log of both database instances
Check the mount point if any breaches the threshold value
Check the application services using adstrtal.sh status service name
2. If loads are normal check Standard manger and queue status
go to System Administrator->concurrent->manager->administer
3. Check the conflict resolution manager’s queue if any.
go to System Administrator->concurrent->manager->administer
select CRM then request
If any request you find in CRM queue , it will automatically make it compatible to run with other request. If not, then check with the user who has submitted the request and clear that.
3.1. To find long running concurrent request:
SELECT a.request_id,a.oracle_process_id "SPID",frt.responsibility_name,c.concurrent_program_name || ': ' || ctl.user_concurrent_program_name,a.description
,a.ARGUMENT_TEXT,b.node_name,b.db_instance,a.logfile_name,a.logfile_node_name,a.outfile_name,q.concurrent_queue_name,a.phase_code,a.status_code, a.completion_text
,actual_start_date,actual_completion_date,fu.user_name,(nvl(actual_completion_date,sysdate)-actual_start_date)*1440 mins,(SELECT avg(nvl(a2.actual_completion_date-a2.actual_start_date,0))*1440 avg_run_time
FROM APPLSYS.fnd_Concurrent_requests a2,APPLSYS.fnd_concurrent_programs c2 WHERE c2.concurrent_program_id = c.concurrent_program_id AND a2.concurrent_program_id = c2.concurrent_program_id
AND a2.program_application_id = c2.application_id AND a2.phase_code || '' = 'C') avg_mins,round((actual_completion_date - requested_start_date),2) * 24 duration_in_hours
FROM APPLSYS.fnd_Concurrent_requests a,APPLSYS.fnd_concurrent_processes b,applsys.fnd_concurrent_queues q,APPLSYS.fnd_concurrent_programs c,APPLSYS.fnd_concurrent_programs_tl ctl
,apps.fnd_user fu,apps.FND_RESPONSIBILITY_TL frt WHERE a.controlling_manager = b.concurrent_process_id AND a.concurrent_program_id = c.concurrent_program_id
AND a.program_application_id = c.application_id AND a.phase_code = 'R' AND a.status_code = 'R' AND b.queue_application_id = q.application_id AND b.concurrent_queue_id = q.concurrent_queue_id
AND ctl.concurrent_program_id = c.concurrent_program_id AND a.requested_by = fu.user_id AND a.responsibility_id = frt.responsibility_id ORDER BY a.actual_start_date DESC;
4. Check the blocking sessions in system:
select
blocking_session,
sid,
serial#,
wait_class,
seconds_in_wait
from
gv$session
where
blocking_session is not NULL
order by blocking session;
If you find blocking session check with user who has submitted the request and clear the request upon confirmation with requestor.
ALTER SYSTEM KILL SESSION 'sid,serial#';
5. Run below command to find SPID, provide concurrent request ID when prompted
SELECT a.request_id, d.sid, d.serial# ,d.osuser,d.process , c.SPID
FROM apps.fnd_concurrent_requests a, apps.fnd_concurrent_processes b, v$process c, v$session d WHERE a.controlling_manager = b.concurrent_process_id AND c.pid = b.oracle_process_id AND b.session_id=d.audsid AND a.request_id = &Request_ID AND a.phase_code = ‘R’;
6.1 Check and confirm SPID on Database Node
ps-ef | grep (SPID) eg : 1523
6.2. Set OSPID (1523 in my case) for ORADEBUG
SQL> oradebug setospid 1523
Step 6.3 : Enable trace for 10050 event with level 12 ( We can give any event number)
SQL> oradebug event 10046 trace name context forever, level 12
6.3. Locate Trace file as
SQL>oradebug tracefile_name
/u01/app/oracle/OTST/12.1.0/admin/OTST_ebdb01/udump/OTST_trace.trc
Wait for 5 minutes
6.4. Disable trace
SQL> oradebug event 10046 trace name context off
6.5. Create tkprof file like
tkprof <filename.trc> <output_filename> sys=no explain=apps/<password> sort='(prsela,exeela,fchela)' print=10
6.6. Check DB alert log file and see any error ( ORA, Tablespace, archive log ) which could be related to issue
adrci
ADRCI: Release 12.1.0.2.0 - Production on Mon Feb 17 22:12:08 2020
Copyright (c) 1982, 2014, Oracle and/or its affiliates. All rights reserved.
ADR base = "/data01/app/oraprd"
adrci> show log
ADR Home = /data01/app/oraprd/diag/rdbms/oprd/OPRD1:
7. Generate the AWR report and compare between the interval of time
Collect Multiple AWR Reports: It's always suggested to have two AWR Reports, one for good time when database was performing well, second when performance is poor).This way we can easily compare good and bad report to find out the culprit.
sql> @$ORACLE_HOME/rdbms/admin/awrgdrpt.sql
8. SQL tuning advisor can be applied to tune the sql statements
SQL profile is a collection of additional statistical information stored in the data dictionary that helps the optimizer to generate the best plan for the query. SQL profile is managed through SQL_TUNE package of SQL tuning advisor. i.e when we run SQL tuning advisor against a query, The tuning optimizer creates a profile for an SQL statement called SQL profile which consists additional statistical information about that statement, and it gives the recommendation to accept that profile.
SQL PROFILE can be applied to below statements.
SELECT statements
UPDATE statements
INSERT statements (only with a SELECT clause)
DELETE statements
CREATE TABLE statements (only with the AS SELECT clause)
MERGE statements (the update or insert operations)
8.1. Run sql tuning advisor for sql_id=5dkrnbx1z8gb
set long 1000000000
Col recommendations for a200
DECLARE
l_sql_tune_task_id VARCHAR2(100);
BEGIN
l_sql_tune_task_id := DBMS_SQLTUNE.create_tuning_task (
sql_id => '5dkrnbx1z8gcb',
scope => DBMS_SQLTUNE.scope_comprehensive,
time_limit => 500,
task_name => '5dkrnbx1z8gb_tuning_task_1',
description => 'Tuning task for statement 5dkrnbx1z8gb');
DBMS_OUTPUT.put_line('l_sql_tune_task_id: ' || l_sql_tune_task_id);
END;
/
EXEC DBMS_SQLTUNE.execute_tuning_task(task_name => '5dkrnbx1z8gb_tuning_task_1');
SET LONG 10000000;
SET PAGESIZE 100000000
SET LINESIZE 200
SELECT DBMS_SQLTUNE.report_tuning_task('5dkrnbx1z8gb_tuning_task_1') AS recommendations FROM dual;
SET PAGESIZE 24
8.2 Go through the profile recommendation part of the report:
DBMS_SQLTUNE.report_tunning: task will generate the completed output of the advisory. If you go through the profile recommendation part, it will be as below.
Recommendation (estimated benefit: we can see the difference multiple of your task) we can check this also through OEM console could be easier to see the % of benefits with the sql profile with multiple of your actual cost.
From the performance tuning advisor tab.
Search for sql_id and see the sql profile with the percentage if above 90% of benefit.
------------------------------------------
- Consider accepting the recommended SQL profile.
execute dbms_sqltune.accept_sql_profile(task_name => '5dkrnbx1z8gb_tuning_task_1', task_owner => 'SYS', replace =>TRUE);
8.3. Accept profile and see the performance of the query.
execute dbms_sqltune.accept_sql_profile(task_name => '5dkrnbx1z8gb_tuning_task_1', task_owner => 'SYS', replace =>TRUE);
9. Gather stats and check when was it last run:
exec fnd_stats.verify_stats('schema', 'object_name');
**************************************************************************************************************************************************
3. The Output Post Processor (OPP):
====================================
The Output Post Processor (OPP) is an enhancement to Concurrent Processing and is designed to support XML Publisher as post-processing action for concurrent requests. If a request is submitted with an XML Publisher template specified as a layout for the concurrent request output, then after the concurrent manager finishes running the concurrent program, it will contact the OPP to apply the XML Publisher template and create the final output.
Here are the steps involved
An application user submits an XML Publisher based report.
The standard concurrent manager processes the request.
The XML data file is generated by the standard concurrent manager.
A post processing action defines that the output needs to be generated by the Output Post Processor ,So standard manager send the request in the queue of OPP
The Output Post Processor generates the final report and informs the standard concurrent manager whether that was successful.
The standard concurrent manager finalizes the concurrent request
The Output Post Processor makes use of the Oracle Streams Advanced Queuing (AQ) database feature. Every OPP service instance monitors the FND_CP_GSM_OPP_AQ queue for new messages and this queue has been created with no value specified for primary_instance (link). This implies that the queue monitor scheduling and propagation is done in any available instance. In other words, ANY OPP service instance may pick up an incoming message independent of the node on which the concurrent request ran.
Maximum Memory Usage Per Process:
The maximum amount of memory or maximum Java heap size a single OPP process can use is by default set to 512MB. This value is seeded by the Loader Data File: $FND_TOP/patch/115/import/US/afoppsrv.ldt which specifies that the DEVELOPER_PARAMETERS is “J:oracle.apps.fnd.cp.gsf.GSMServiceController:-mx512m”.
How to determine the current maximum Java heap size:
SELECT service_id, service_handle, developer_parameters
FROM fnd_cp_services
WHERE service_id = (SELECT manager_type
FROM fnd_concurrent_queues
WHERE concurrent_queue_name = ‘FNDCPOPP’);SERVICE_ID SERVICE_HANDLE DEVELOPER_PARAMETERS
———- ————– ——————————————————–
1091 FNDOPP J:oracle.apps.fnd.cp.gsf.GSMServiceController:-mx512m
Increase the maximum Java heap size for the OPP to 1024MB (1GB):
UPDATE fnd_cp_services
SET developer_parameters =
‘J:oracle.apps.fnd.cp.gsf.GSMServiceController:-mx1024m’
WHERE service_id = (SELECT manager_type
FROM fnd_concurrent_queues
WHERE concurrent_queue_name = ‘FNDCPOPP’);
The OPP queue can be Recreated the using $FND_TOP/patch/115/sql/afopp002.sql file as ‘APPLSYS’ user. On running the script you will be prompted for username and password.
There are 2 new profiles options that can be used to control the timeouts
Profile Option : Concurrent:OPP Response Timeout
Internal Name : CONC_PP_RESPONSE_TIMEOUT
Description : Specifies the amount of time a manager waits for OPP to respond to its request for post processing.
Profile Option : Concurrent:OPP Process Timeout
Internal Name : CONC_PP_PROCESS_TIMEOUT
Description : Specifies the amount of time the manager waits for the OPP to actually process the request.
***************************************************************************************************************************************
4. Concurrent Request Status Codes and Meaning Of Status Code's
Normally a concurrent request proceeds through three, possibly four, life cycle stages or phases,
Phase Code
Meaning with Description
Pending
Request is waiting to be run
Running
Request is running
Completed
Request has finished
Inactive
Request cannot be run
Within each phase, a request's condition or status may change. Below appears a listing of each phase and the various states that a concurrent request can go through.
The status and the description of each meaning given below:
PENDING
Normal
Request is waiting for the next available manager.
Standby
Program to run request is incompatible with other program(s) currently running.
Scheduled
Request is scheduled to start at a future time or date.
Waiting
A child request is waiting for its Parent request to mark it ready to run. For example, a report in a report set that runs sequentially must wait for a prior report to complete.
RUNNING
Normal
Request is running normally.
Paused
Parent request pauses for all its child requests to complete. For example, a report set pauses for all reports in the set to complete.
Resuming
All requests submitted by the same parent request have completed running. The Parent request is waiting to be restarted.
Terminating
Running request is terminated, by selecting Terminate in the Status field of the Request Details zone.
COMPLETED
Normal
Request completes normally.
Error
Request failed to complete successfully.
Warning
Request completes with warnings. For example, a report is generated successfully but fails to print.
Cancelled
Pending or Inactive request is cancelled, by selecting Cancel in the Status field of the Request Details zone.
Terminated
Running request is terminated, by selecting Terminate in the Status field of the Request Details zone.
INACTIVE
Disabled
Program to run request is not enabled. Contact your system administrator.
On Hold
Pending request is placed on hold, by selecting Hold in the Status field of the Request Details zone.
No Manager
No manager is defined to run the request. Check with your system administrator.
*************************************************
5. FNDFS and FNDSM in Oracle R12:
==============================
FNDFS or the Report Review Agent (RRA) is the default text viewer within Oracle Applications, which allows users to view report output and log files. Report Review Agent is also referred to by the executable FNDFS. The default viewer must be configured correctly before external editors or browsers are used for viewing requests.
FNDSM is the Service manager. FNDSM is executable & core component in GSM ( Generic Service Management Framework ). You start FNDSM services via APPS listener on all Nodes in Application Tier.
There are certain scenario where we can't see the output of Concurrent Requests. It just gives an error.
Then check the fndwrr.exe size in production and compare it with Test Instance.
fndwrr.exe is present in $FND_TOP/bin
If there is any difference then relink the FNDFS executable.It might not be in sync with the binaries.
Command for relinking
adrelink.sh force=y "fnd FNDFS"
****************************************************************
6. Troubleshooting EBS 12.2 login page errors
EBS login flow and importance of users such as GUEST, APPS and APPLSYS. In this post we will see what to look for when we face some issues while accessing the EBS login page.
Troubleshooting EBS login page issue
1. If the login page doesn't comes up then we have to focus on the varios logs present under $LOG_HOME directory. In case of EBS 12.2(as it is the latest release),
1) OHS (apache) failure
If OHS is not running or not responding, one would see a message as below. If OHS is not running then there will not be any messages in any EBS log file for this request.
Firefox: “The connection was reset”
Steps to take
Check OHS has started OK
adapcctl.sh status
adapcctl.sh stop
adapcctl.sh start
2 OACore JVM process not available
If the OACore JVM is not running or not reachable, then one will likely see the following message in the browser:
Failure of server APACHE bridge:
No backend server available for connection: timed out after 10 seconds or idempotent set to OFF or method not idempotent.
There could be two reason
Steps to take
a)Make sure the OACore JVM has started correctly
admanagedsrvctl.sh start oacore
b) Check mod_wl_ohs.conf file is configured correctly
3) oacore J2EE application not available
There may be cases where the OACore JVM is running and reachable but the oacore application is not available.
The browser will report the error:
Error 404–Not Found
From RFC 2068 Hypertext Transfer Protocol — HTTP/1.1:
10.4.5 404 Not Found
The server has not found anything matching the Request-URI. No indication is given of whether the condition is temporary or permanent.
Access_log will show 404 error:
GET /OA_HTML/AppsLogin HTTP/1.1″ 404
Steps to take
In the FMW Console check the “deployments” to confirm the “oacore” application is at status “Active” and Health is “OK”.
4) Datasource failure
The oacore logs will show this type of error
<Error> <ServletContext-/OA_HTML> <BEA-000000> <Logging call failed exception::
java.lang.NullPointerException
at oracle.apps.fnd.sso.AppsLoginRedirect.logSafe(AppsLoginRedirect.java:639)
at oracle.apps.fnd.sso.AppsLoginRedirect.doGet(AppsLoginRedirect.java:1314)
at javax.servlet.http.HttpServlet.service(HttpServlet.java:707)
The explorer will show
The system has encountered an error while processing your request.Please contact your system administrator
Steps to Take
Review the EBS Datasource and make sure it is targeted to the oacore_cluster1 managed server. Also use the “Test Datasource” option to confirm database connection can be made
If one makes any changes, one will need to restart the managed server.
Once we get the ebs login page and upon passing the credentials, if we are not getting the home page then we should focus on
1. Check the OHS files and see if they are correct or not
2. APPL_SERVER_ID in dbc file matches with server ID in FND_NODES table against respective Server
3. GUEST/ORACLE password is correct & user is not end dated
4. APPS and APPlSYS password should be same
*********************************************************************************
Check Value in DBC File
[test appl]$ grep -i GUEST_USER_PWD $FND_SECURE/visr12.dbc
GUEST_USER_PWD=GUEST/ORACLE
Check profile option value in DB
[test appl]$ sqlplus apps/
SQL> select fnd_profile.value('GUEST_USER_PWD') from dual;
FND_PROFILE.VALUE(’GUEST_USER_PWD’)
——————————————————————————–
GUEST/ORACLE
Value for step 1 and 2 must be sync
Guest user connectivity check
SQL> select FND_WEB_SEC.VALIDATE_LOGIN('GUEST','ORACLE') from dual;
FND_WEB_SEC.VALIDATE_LOGIN('GUEST','ORACLE')
——————————————————————————–-----
Y
proper configuration should return it as Y
4. Compile JSP
[test appl]$ cd $FND_TOP/patch/115/bin
[test bin]$ ojspCompile.pl --compile --flush
**************************************************************************************************
5. There is JSP tool test to find most of issues via
http://host.domain:port/OA_HTML/jsp/fnd/aoljtest.jsp
Reference: 12.2 E-Business Suite Technology Stack Summary Of The iAS / HTTP Server Login Process And What To Expect When One Of The Login Components Fails (Doc ID 1984710.1)
******************************************************************************************************************888888888888******************
7. Java Forms opening issue in EBS (R12):
let’s first understand about Oracle Forms, it can be configured in two modes: servlet and socket.
In servlet mode, a Java servlet (called the Forms Listener servlet) manages the communication between the Forms Java client and the OracleAS Forms services. In socket mode, the desktop
clients access the Forms server directly.
To know more about Oracle Forms check our post Oracle Apps R12 Forms: Servlet or Socket
Issue:
We were trying to access System Administrator -> Define Profile Options but Java plugins were not working due to which forms are not opening:
Fix: clinet desktop.
1. Copy the URL that you are unable to open. In our case 1704ebs54.k21technologies.com:8000
2. Open Control panel, then search for Java and click on that.
3. Click on Security
4. Click the “Edit Site List…”
5. 5. Click on Add and Paste the URL into the “Location” text box then click OK
7. Click OK on Java Control Panel and reload the page
****************************************************************************************************************************************************
8. About Oracle Application Framework in EBS:
=========================================
Oracle Application Framework (OAF) is an architecture for creating web based front end pages and J2EE type of applications within the Oracle EBS ERP platform.Oracle Application Framework is
the development and deployment platform developed by Oracle to develop the Oracle E-Business Suite “Self-Service” or HTML based Applications.
II). Concurrent Program:
How to Tune Concurrent Manager?
++++++++++++++++++++++++++++++++
There are 5 ways to faster your CM
1.PMON cycle, queue size, and sleep time.
2.Purging Concurrent Requests
3.Adjusting the Concurrent Manager Cache Size
4.Analyzing Oracle Apps Dictionary Tables for High Performance
5. Number of Standard Managers
1.PMON cycle, queue size, and sleep time.
The ICM performance is affected by the three important Oracle parameters
PMON cycle
This is the number of sleep cycles that the ICM waits between the time it checks for concurrent managers failures, are having problems with abnormal terminations.
Queue Size
The queue size is the number of PMON cycles that the ICM waits between checking for disabled or new concurrent managers. The default for queue size of 1 PMON cycle should be used.
Sleep Time
The sleep time parameter indicates the seconds that the ICM should wait between checking for requests that are waiting to run. The default sleep time is 60, but you can lower this number if
you see you have a lot of request waiting (Pending/Normal). However, reducing this number to a very low value many cause excessive cpu utilization.
2.Purging Concurrent Requests
One important area of Concurrent Manager tuning is monitoring the space usage for the subsets within each concurrent manager.
When the space in FND_CONCURRENT_PROCESSES and FND_CONCURRENT_REQUESTS exceed 50K, you can start to experience serious performance problems within your Oracle Applications. When you
experience these space problems, a specific request called “Purge Concurrent Requests And/Or Manager Data” should be scheduled to run on a regular basis. This request can be configured to
purge the request data from the FND tables as well as the log files and output files on accumulate on disk.
3.Adjusting the Concurrent Manager Cache Size
Concurrent manager performance can also be enhanced by increasing the manager cache size to be at lease twice the number of target processes. The cache size specifies the number of requests
that will be cached each time the concurrent manager reads from the FND_CONCURRENT_REQUESTS table. Increasing the cache size will boost the throughput of the managers by attempting to avoid
sleep time.
4.Analyzing Oracle Apps Dictionary Tables for High Performance
We can generate statistics that quantify the data distribution and storage characteristics of tables, columns,indexes, and partitions. The cost-based optimization approach uses these
statistics to calculate the selectivity of predicates and to estimate the cost of each execution plan. Selectivity is the fraction of rows in a table that the SQL statement’s predicate
chooses. The optimizer uses the selectivity of a predicate to estimate the cost of a particular access method and to determine the optimal join order and join method.
We should gather statistics periodically for objects where the statistics become stale over time because of changing data volumes or changes in column values. New statistics should be
gathered after a schema object’s data or structure are modified in ways that make the previous statistics inaccurate. For example, after loading a significant number of rows
into a table, collect new statistics on the number of rows. After updating data in a table, you do not need to collect new statistics on the number of rows, but you might need new statistics
on the average row length.
It is also very important to run the request Gather Table Statistics on these tables:
FND_CONCURRENT_PROCESSES
FND_CONCURRENT_PROGRAMS
FND_CONCURRENT_REQUESTS
FND_CONCURRENT_QUEUES.
5. Number of Standard Managers
Some of environments are copies of other environments, and you may find that the number of Standard Concurrent Managers are just 5. You can increase this to say 10 or 15, this will help the
pending requests queue is not getting too long & the Conflict Resolution Manager will have less load
********************************************************************************************************
2. Long running concurrent Program Suppose it DB side Issue:
============================================================
1. Sanity checks
Top Free -g
Check alert log of both database instances
Check the mount point if any breaches the threshold value
Check the application services using adstrtal.sh status service name
2. If loads are normal check Standard manger and queue status
go to System Administrator->concurrent->manager->administer
3. Check the conflict resolution manager’s queue if any.
go to System Administrator->concurrent->manager->administer
select CRM then request
If any request you find in CRM queue , it will automatically make it compatible to run with other request. If not, then check with the user who has submitted the request and clear that.
3.1. To find long running concurrent request:
SELECT a.request_id,a.oracle_process_id "SPID",frt.responsibility_name,c.concurrent_program_name || ': ' || ctl.user_concurrent_program_name,a.description
,a.ARGUMENT_TEXT,b.node_name,b.db_instance,a.logfile_name,a.logfile_node_name,a.outfile_name,q.concurrent_queue_name,a.phase_code,a.status_code, a.completion_text
,actual_start_date,actual_completion_date,fu.user_name,(nvl(actual_completion_date,sysdate)-actual_start_date)*1440 mins,(SELECT avg(nvl(a2.actual_completion_date-a2.actual_start_date,0))*1440 avg_run_time
FROM APPLSYS.fnd_Concurrent_requests a2,APPLSYS.fnd_concurrent_programs c2 WHERE c2.concurrent_program_id = c.concurrent_program_id AND a2.concurrent_program_id = c2.concurrent_program_id
AND a2.program_application_id = c2.application_id AND a2.phase_code || '' = 'C') avg_mins,round((actual_completion_date - requested_start_date),2) * 24 duration_in_hours
FROM APPLSYS.fnd_Concurrent_requests a,APPLSYS.fnd_concurrent_processes b,applsys.fnd_concurrent_queues q,APPLSYS.fnd_concurrent_programs c,APPLSYS.fnd_concurrent_programs_tl ctl
,apps.fnd_user fu,apps.FND_RESPONSIBILITY_TL frt WHERE a.controlling_manager = b.concurrent_process_id AND a.concurrent_program_id = c.concurrent_program_id
AND a.program_application_id = c.application_id AND a.phase_code = 'R' AND a.status_code = 'R' AND b.queue_application_id = q.application_id AND b.concurrent_queue_id = q.concurrent_queue_id
AND ctl.concurrent_program_id = c.concurrent_program_id AND a.requested_by = fu.user_id AND a.responsibility_id = frt.responsibility_id ORDER BY a.actual_start_date DESC;
4. Check the blocking sessions in system:
select
blocking_session,
sid,
serial#,
wait_class,
seconds_in_wait
from
gv$session
where
blocking_session is not NULL
order by blocking session;
If you find blocking session check with user who has submitted the request and clear the request upon confirmation with requestor.
ALTER SYSTEM KILL SESSION 'sid,serial#';
5. Run below command to find SPID, provide concurrent request ID when prompted
SELECT a.request_id, d.sid, d.serial# ,d.osuser,d.process , c.SPID
FROM apps.fnd_concurrent_requests a, apps.fnd_concurrent_processes b, v$process c, v$session d WHERE a.controlling_manager = b.concurrent_process_id AND c.pid = b.oracle_process_id AND b.session_id=d.audsid AND a.request_id = &Request_ID AND a.phase_code = ‘R’;
6.1 Check and confirm SPID on Database Node
ps-ef | grep (SPID) eg : 1523
6.2. Set OSPID (1523 in my case) for ORADEBUG
SQL> oradebug setospid 1523
Step 6.3 : Enable trace for 10050 event with level 12 ( We can give any event number)
SQL> oradebug event 10046 trace name context forever, level 12
6.3. Locate Trace file as
SQL>oradebug tracefile_name
/u01/app/oracle/OTST/12.1.0/admin/OTST_ebdb01/udump/OTST_trace.trc
Wait for 5 minutes
6.4. Disable trace
SQL> oradebug event 10046 trace name context off
6.5. Create tkprof file like
tkprof <filename.trc> <output_filename> sys=no explain=apps/<password> sort='(prsela,exeela,fchela)' print=10
6.6. Check DB alert log file and see any error ( ORA, Tablespace, archive log ) which could be related to issue
adrci
ADRCI: Release 12.1.0.2.0 - Production on Mon Feb 17 22:12:08 2020
Copyright (c) 1982, 2014, Oracle and/or its affiliates. All rights reserved.
ADR base = "/data01/app/oraprd"
adrci> show log
ADR Home = /data01/app/oraprd/diag/rdbms/oprd/OPRD1:
7. Generate the AWR report and compare between the interval of time
Collect Multiple AWR Reports: It's always suggested to have two AWR Reports, one for good time when database was performing well, second when performance is poor).This way we can easily compare good and bad report to find out the culprit.
sql> @$ORACLE_HOME/rdbms/admin/awrgdrpt.sql
8. SQL tuning advisor can be applied to tune the sql statements
SQL profile is a collection of additional statistical information stored in the data dictionary that helps the optimizer to generate the best plan for the query. SQL profile is managed through SQL_TUNE package of SQL tuning advisor. i.e when we run SQL tuning advisor against a query, The tuning optimizer creates a profile for an SQL statement called SQL profile which consists additional statistical information about that statement, and it gives the recommendation to accept that profile.
SQL PROFILE can be applied to below statements.
SELECT statements
UPDATE statements
INSERT statements (only with a SELECT clause)
DELETE statements
CREATE TABLE statements (only with the AS SELECT clause)
MERGE statements (the update or insert operations)
8.1. Run sql tuning advisor for sql_id=5dkrnbx1z8gb
set long 1000000000
Col recommendations for a200
DECLARE
l_sql_tune_task_id VARCHAR2(100);
BEGIN
l_sql_tune_task_id := DBMS_SQLTUNE.create_tuning_task (
sql_id => '5dkrnbx1z8gcb',
scope => DBMS_SQLTUNE.scope_comprehensive,
time_limit => 500,
task_name => '5dkrnbx1z8gb_tuning_task_1',
description => 'Tuning task for statement 5dkrnbx1z8gb');
DBMS_OUTPUT.put_line('l_sql_tune_task_id: ' || l_sql_tune_task_id);
END;
/
EXEC DBMS_SQLTUNE.execute_tuning_task(task_name => '5dkrnbx1z8gb_tuning_task_1');
SET LONG 10000000;
SET PAGESIZE 100000000
SET LINESIZE 200
SELECT DBMS_SQLTUNE.report_tuning_task('5dkrnbx1z8gb_tuning_task_1') AS recommendations FROM dual;
SET PAGESIZE 24
8.2 Go through the profile recommendation part of the report:
DBMS_SQLTUNE.report_tunning: task will generate the completed output of the advisory. If you go through the profile recommendation part, it will be as below.
Recommendation (estimated benefit: we can see the difference multiple of your task) we can check this also through OEM console could be easier to see the % of benefits with the sql profile with multiple of your actual cost.
From the performance tuning advisor tab.
Search for sql_id and see the sql profile with the percentage if above 90% of benefit.
------------------------------------------
- Consider accepting the recommended SQL profile.
execute dbms_sqltune.accept_sql_profile(task_name => '5dkrnbx1z8gb_tuning_task_1', task_owner => 'SYS', replace =>TRUE);
8.3. Accept profile and see the performance of the query.
execute dbms_sqltune.accept_sql_profile(task_name => '5dkrnbx1z8gb_tuning_task_1', task_owner => 'SYS', replace =>TRUE);
9. Gather stats and check when was it last run:
exec fnd_stats.verify_stats('schema', 'object_name');
**************************************************************************************************************************************************
3. The Output Post Processor (OPP):
====================================
The Output Post Processor (OPP) is an enhancement to Concurrent Processing and is designed to support XML Publisher as post-processing action for concurrent requests. If a request is submitted with an XML Publisher template specified as a layout for the concurrent request output, then after the concurrent manager finishes running the concurrent program, it will contact the OPP to apply the XML Publisher template and create the final output.
Here are the steps involved
An application user submits an XML Publisher based report.
The standard concurrent manager processes the request.
The XML data file is generated by the standard concurrent manager.
A post processing action defines that the output needs to be generated by the Output Post Processor ,So standard manager send the request in the queue of OPP
The Output Post Processor generates the final report and informs the standard concurrent manager whether that was successful.
The standard concurrent manager finalizes the concurrent request
The Output Post Processor makes use of the Oracle Streams Advanced Queuing (AQ) database feature. Every OPP service instance monitors the FND_CP_GSM_OPP_AQ queue for new messages and this queue has been created with no value specified for primary_instance (link). This implies that the queue monitor scheduling and propagation is done in any available instance. In other words, ANY OPP service instance may pick up an incoming message independent of the node on which the concurrent request ran.
Maximum Memory Usage Per Process:
The maximum amount of memory or maximum Java heap size a single OPP process can use is by default set to 512MB. This value is seeded by the Loader Data File: $FND_TOP/patch/115/import/US/afoppsrv.ldt which specifies that the DEVELOPER_PARAMETERS is “J:oracle.apps.fnd.cp.gsf.GSMServiceController:-mx512m”.
How to determine the current maximum Java heap size:
SELECT service_id, service_handle, developer_parameters
FROM fnd_cp_services
WHERE service_id = (SELECT manager_type
FROM fnd_concurrent_queues
WHERE concurrent_queue_name = ‘FNDCPOPP’);SERVICE_ID SERVICE_HANDLE DEVELOPER_PARAMETERS
———- ————– ——————————————————–
1091 FNDOPP J:oracle.apps.fnd.cp.gsf.GSMServiceController:-mx512m
Increase the maximum Java heap size for the OPP to 1024MB (1GB):
UPDATE fnd_cp_services
SET developer_parameters =
‘J:oracle.apps.fnd.cp.gsf.GSMServiceController:-mx1024m’
WHERE service_id = (SELECT manager_type
FROM fnd_concurrent_queues
WHERE concurrent_queue_name = ‘FNDCPOPP’);
The OPP queue can be Recreated the using $FND_TOP/patch/115/sql/afopp002.sql file as ‘APPLSYS’ user. On running the script you will be prompted for username and password.
There are 2 new profiles options that can be used to control the timeouts
Profile Option : Concurrent:OPP Response Timeout
Internal Name : CONC_PP_RESPONSE_TIMEOUT
Description : Specifies the amount of time a manager waits for OPP to respond to its request for post processing.
Profile Option : Concurrent:OPP Process Timeout
Internal Name : CONC_PP_PROCESS_TIMEOUT
Description : Specifies the amount of time the manager waits for the OPP to actually process the request.
***************************************************************************************************************************************
4. Concurrent Request Status Codes and Meaning Of Status Code's
Normally a concurrent request proceeds through three, possibly four, life cycle stages or phases,
Phase Code
Meaning with Description
Pending
Request is waiting to be run
Running
Request is running
Completed
Request has finished
Inactive
Request cannot be run
Within each phase, a request's condition or status may change. Below appears a listing of each phase and the various states that a concurrent request can go through.
The status and the description of each meaning given below:
PENDING
Normal
Request is waiting for the next available manager.
Standby
Program to run request is incompatible with other program(s) currently running.
Scheduled
Request is scheduled to start at a future time or date.
Waiting
A child request is waiting for its Parent request to mark it ready to run. For example, a report in a report set that runs sequentially must wait for a prior report to complete.
RUNNING
Normal
Request is running normally.
Paused
Parent request pauses for all its child requests to complete. For example, a report set pauses for all reports in the set to complete.
Resuming
All requests submitted by the same parent request have completed running. The Parent request is waiting to be restarted.
Terminating
Running request is terminated, by selecting Terminate in the Status field of the Request Details zone.
COMPLETED
Normal
Request completes normally.
Error
Request failed to complete successfully.
Warning
Request completes with warnings. For example, a report is generated successfully but fails to print.
Cancelled
Pending or Inactive request is cancelled, by selecting Cancel in the Status field of the Request Details zone.
Terminated
Running request is terminated, by selecting Terminate in the Status field of the Request Details zone.
INACTIVE
Disabled
Program to run request is not enabled. Contact your system administrator.
On Hold
Pending request is placed on hold, by selecting Hold in the Status field of the Request Details zone.
No Manager
No manager is defined to run the request. Check with your system administrator.